![[Kubernetes 공식문서 파헤치기] 고가용성 테스트(pod 부하분산, auto scaler 적용하기)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcEWOgW%2FbtqGCoGda5Q%2FAAAAAAAAAAAAAAAAAAAAABPWJBIAVFYmszNNSfeAp1NDrh5W4jHK5toE-Mdw2isO%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DKqO2BqMJP%252Fpk8TDhgC1HisjX1mI%253D)
앞의 내용에서 이어서 진행합니다.
[Kubernetes 공식문서 파헤치기] Redis를 사용한 PHP 방명록 애플리케이션 배포하기 + PV, PVC, Affinity 사용해보기
고가용성
고가용성이란 "서버, 네트워크, 프로그램같은 시스템이 절대 고장나지 않고 오랫동안 유지하는 능력"을 얘기합니다.
그럼 쿠버네티스에서의 고가용성 또한 다르지 않을겁니다.
그럼 쿠버네티스가 고장나는 상황은 무엇일까요?
1. 사용자가 많아져서 서버가 제 역할을 하지 못한다.
2. 애플리케이션이 동작하는 도중에는 예상치못한 중지들이 생길 수 있다.
3. 관리자가 쿠버네티스를 관리하다가 실수로 pod, node들을 중지시킬 수 있다.
4. 클라우드 제공 업체에서 제공해주는 클러스터에 대한 자원이 부족할 때
해결 방안
1번에 대한 해결 방안들
- 서버 증설
Node의 수를 늘림으로써 트래픽을 감당할 수 있는 서버를 늘리는 방법이 있습니다.
하지만 자원 자체를 늘리는 것은 관리자가 신경쓰는 부분이 아닙니다.
관리자는 가지고있는 자원을 이용해서 어떻게 고장이 안나게 하는가에 신경을 써야합니다.
- 트래픽에 대한 부하 분산
파드에 어피니티를 적용하여 하나의 노드에만 자원이 과도하게 할당되는 것을 막습니다.
또는 파드 오토스케일링을 적용하여 자원 사용량에 따라 pod가 유동적으로 scale up 또는 scale down이 되면서
트래픽에 대한 대비를 합니다.
2번에 대한 해결 방안들
- 실행 보장
디플로이먼트, 레플리카풀셋 ,스테이트풀셋등 파드의 실행을 보장시켜주는 오브젝트를 이용합니다.
3번에 대한 해결 방안들
- 중지 방지
실수로 중지, 고의로 중지를 할 때 최소한의 Pod를 보장해주는 Pod Disruption Budget(PDB)를 사용하여
관리자가 실수로 중지를 하려할 때 실행가능한 Pod의 개수를 확인하여 중지를 방지하는 방법이 있습니다.

공식문서에서 모든 자발적인 중단이 PDB에 연관되는 것은 아니라고 합니다. (= PDB가 모든 자발적인 중단을 해결할 수 없다.)
그럼 우리가 신경써야하는 중지는 무엇일까요?
노드 소프트웨어의 업데이트를 출시하는 경우 자발적 중단이 일어날 수 있습니다. (노드 드레이닝)
그리고 노드 오토스케일링의 일부 구현에서 단편화를 제거하고 노드의 효율을 높이는 과정에서도 중단을 야기할 수 있습니다.
혹은 노드에 다른 무언가를 추가하기 위해 파드를 제거할 때도 일어날 수 있습니다.
4번에 대한 해결 방안들
클라우드 컴퓨팅의 신조 중 하나는 사용한 만큼만 지불하는 자원소비입니다.
우리가 필요할 때 필요한 만큼만 클라우드 서비스를 사용할 수 있습니다.
클라우드 제공 업체와 소통하여, 사용량이 많을 때는 추가 노드를 요청하거나
사용량이 적을 때는 노드를 종료해 인프라스트럭처 비용을 낮출 수 있습니다.
노드를 Scale up 하거나 Scale down하는 방법 크게 두 가지가 있을 수 있습니다.
우리가 할 수 있는 것들
1. 애플리케이션이 실행될 때 트래픽이 잘 분산되는가를 확인해봅니다.
- 어피니티를 적용하여 각각의 노드에 할당되는 메모리와 CPU를 줄인다.
이 방식은 자원을 충족시키기 위해 수동으로 레플리카를 늘립니다.
2. 파드의 수평적 오토스케일링(애플리케이션 사용자가 많아져서 트래픽이 많아졌을 때 파드가 잘 늘어나는가)
- 일정 CPU 사용량이 증가하면 자동적으로 Pod를 증설하여 트래픽을 분산시킨다.
- 맨 처음부터 replicas를 많이 생성하지말고 사용자가 없을 때에는 scale down을 하여 자원량을 아낀다.
이 방식은 1번과 다르게 자동으로 레플리카를 늘리는 방법입니다.
3. 노드가 갑자기 꺼졌을 때 노드에서 실행되고있던 파드가 다른 노드로 잘 옮겨지는가
4. 노드 업데이트를 위해 노드 드레이닝을 실행할 때 최소한의 파드의 수를 보장해주는가
5. 클러스터의 오토스케일링에 간단히
1. Pod의 CPU를 과부하를 줘서 트래픽이 잘 분산되는지 확인해보기.
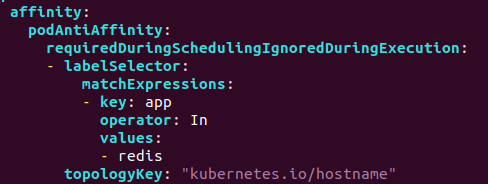
frontend-deployment.yaml
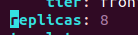
고가용성 테스트를 위해서 replicas의 개수를 8개로 늘렸습니다.

저는 kubespray로 kubernetes를 설치할 때
metric server를 설치했기 때문에 CPU와 Memory에 대한 트래픽들을 확인할 수 있습니다.
kubectl top pod (or node)pod나 node의 CPU, MEMORY 사용량을 보고싶다면 저 위 명령을 사용하면 됩니다.
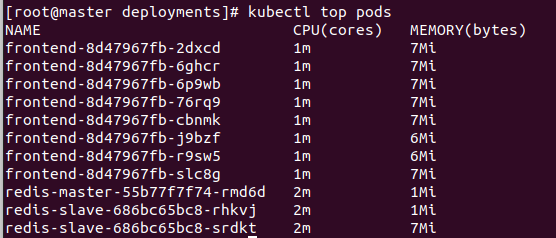
Pod 트래픽 분산 테스트를 하기 위해서 애플리케이션에
http 요청을 계속해서 분산을 줘서 CPU 사용량이 골고루 증가하는지 확인해보았습니다.
while true;do curl 192.168.100.66:30398;done(위 명령어는 다른 커맨드창을 켜서 하는게 좋습니다.)
저희 애플리케이션 주소는 NodePort로 접속되어있기 때문에
열려있는 NodePort로 접속하기만 하면 frontend pod로 라우팅해줍니다.
위 명령어를 입력 후 10초? 20초 정도 기다리면
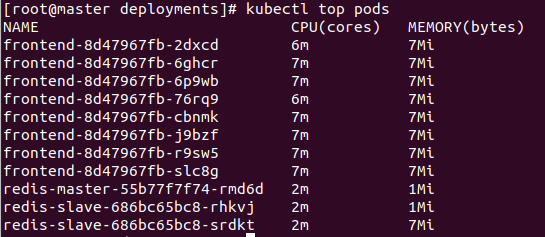
트래픽이 골고루 나뉘어서 분산되는 것을 볼 수 있습니다.
2. PodAutoScaler 적용해보기 (오토 스케일링)
파드 오토 스케일링 중에서도 두 가지로 나뉩니다.
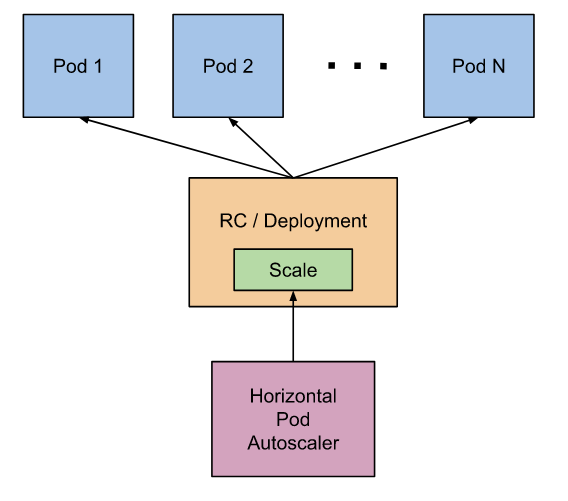
1. 수평적 파드 오토 스케일링(HorizontalPodAutoscaler)
= HPA는 파드 레플리카를 더 많이 만드는것과 같습니다.
2. 수직적 파드 오토 스케일링(VerticalPodAutoscaler)
= VPA는 파드가 관리하는 컨테이너를 실행하는데 더 많은 자원을 제공함과 같은 의미입니다.
- 수평적 파드 오토 스케일링(HorizontalPodAutoscaler)
HPA가 작동하려면 두 가지의 조건이 요구됩니다.
첫번째는 CPU에 대한 requests 제한을 디플로이먼트에 선언을 해야합니다.
두번째는 클러스터 전체의 자원 사용량 데이터를 집계하는 메트릭 서버를 활성화 하는 것입니다.
HPA의 작동원리는 관리자가 HPA를 정의하면 정의에 따라 스케일링될 파드에 대한 메트릭을 가져옵니다.
현재 메트릭 값과 목표하는 요청한 메트릭 값을 기반으로 필요한 레플리카 수를 계산하고
그 레플리카 수 만큼의 파드를 자동적으로 UP, DOWN을 해주는 원리입니다.
말은 쉬워보이지만 실제는
여러 개의 파드 인스턴스를 고려해야 하고
여러 메트릭의 타입을 다뤄야 하고
다양한 예외 사례와 변동하는 값까지 고려를 해야하기 때문에 더욱 복잡합니다.
만약 여러 메트릭이 지정된 경우에는 HPA는 각 메트릭을 개별적으로 평가한 후 가장 큰 값을 제안합니다.
계산이 모두 끝나면 "요청한 레플리카 수"라는 정수 형태로 계산이 될 것입니다.
- 수직적 파드 오토 스케일링(VerticalPodAutoscaler)
VPA는 HPA보다 덜 사용되고, 아직 베타 서비스입니다.
파드가 생성될 때 메모리나 CPU요구량을 적절하게 해주지않으면노드의 CPU 고갈, 성능이 저하되거나 너무 많이 요구하면 불필요한 용량이 할당되어서 자원이 낭비될 수 있습니다.
그래서 VPA는 가능한 정확하게 자원을 요청하는 것이 중요합니다.
updateMode의 종류에 따라 VPA가 작동하는 방식이다릅니다.
1. updateMode : "Off"VPA Off모드는 파드 메트릭과 이벤트를 수집한 후 권장사항을 생성하고권장하는 메모리 혹은 CPU양을 저장하기만하고 나머지 동작사항은 없습니다.
2. updateMode : "Initial"VPA Initial 모드는 Off에서 한 단계 더 나아가서VPA 어드미션 플러그인을 활성화하여 새로 생성된 파드에만 권장사항을 적용합니다.한 마디로 기존의 pod에는 영향을 주지않고, 새로 생성되는 pod에만 적절한 자원양을할당하는 모드입니다.
3. updateMode: "Auto"Auto 모드는 현재 실행중인 파드를 전부 축출하고 파드를 재생성해서 자원요청을 업데이트합니다.그래서 많은 중단을 일으키는 모드이고, 이 모드를 실행하기전 충분한 테스트가 선행되어야 합니다.
VPA는 아직 베타버전이고 실습은 패스했습니다.
실습
고가용성 기술중 대표적인 기술인 HorizontalPodAutoscaler 를 적용시켜보겠습니다.
Auto scale 기술은 pod의 자원량과 트래픽에 따라서 replicas의 개수가 유기적으로 변하는 것입니다.
HorizontalPodAutoscaler는 yaml파일로 생성할 수도있고 커맨드 한 줄로도 간단히 생성할 수 있습니다.

frontend deployment의 이름을 알아야합니다.

kubectl autoscale deployment frontend --cpu-percent=50 --min=1 --max=10
kubectl = kubectl 명령어로 생성을 할 수 있습니다.
autoscale = autoscaler를 생성하겠다.
deployment frontend = frontend의 이름을가진 deployment의 autoscale을 생성하겠다.
--cpu-percent = CPU 사용량이 요구한 것의 50%가 넘어가면 pod를 scale하겠다.
--min=1 = CPU 사용량이 없을 때는 pod가 최소 하나 유지하겠다.
--max=10 = CPU 사용량에 따라 pod를 최대 10개까지 늘리겠다.

kubectl get hpaTARGETS는 pod들의 CPU사용량의 평균을 나타내는 것인데
<unknown> 이라고 뜬 것은 제가 frontend에 CPU 자원량을 적어주지 않아서 그렇습니다.
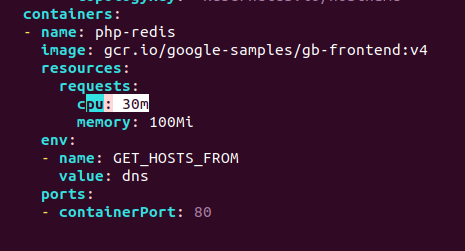
CPU 요구량을 적어주고 deployment와 autoscaler를 둘 다 새로적용시켜줍니다.
그리고 조금 기다리면

다음과 같이 나오는것을 볼 수 있습니다. (디플로이먼트에서 Replicas도 1로 바꿨습니다. 테스트를 위해서)
그리고 테스트를 위해서 요청을 계속 보내봅니다.
while true;do curl 192.168.100.66:30398;done
커맨드창 여러 개를 띄워놓고 테스트를 했습니다.
총 4개를 띄워봤습니다.
kubectl get hpa
총 8개의 파드가 복제되었고
파드들의 평균 CPU 사용량은 50%라는 뜻입니다.
저희가 50%를 MAX로 설정해놔서 50%가 넘어가면 복제본 파드를 생성합니다.
kubectl get pods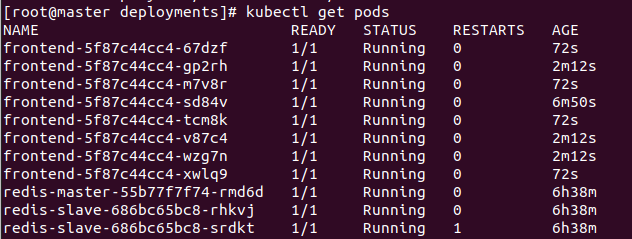
총 8개의 POD가 생성된 것을 볼 수있습니다.
kubectl top pods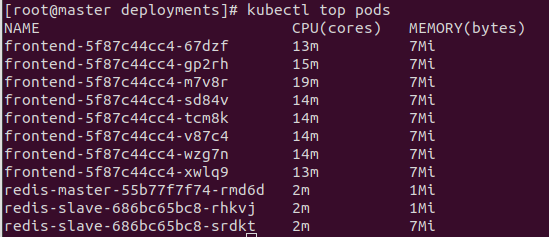
CPU 사용량을 자세히보면
저희가 디플로이먼트를 생성할 때 CPU요구량을 30m로 설정해줬기 때문에
autoscale에서 50%는 15m을 말합니다.
그래서 15m이 평균이되고, 그것을 넘으면 파드를 새로 생성하는 원리입니다.

트래픽을 중지시켰을 때에는 이렇게 나오고
scale down이 되는 시간은 default 300초로 6분이 지나고나면
자동적으로 복제본 pod가 없어집니다.


스케일 다운이 되고나서 pods와 autoscaler의 상태입니다.
3. Pod Disruption Budget(PDB)

pdb.yaml
노드를 인위적으로 줄일 경우(Voluntary disruptions) 그 노드에 Pod가 여러개 돌고 있을 경우 순간적으로 Pod의 수가 줄어들 수 있다. 예를 들어 웹 서버 Pod가 노드1에 5개, 노드 2에 8개가 돌고 있을 때 노드1을 다운 시키면 순간적으로 Pod의 총 수가 8개가 된다. replica수에 의해서 복귀는 되겠지만, 성능을 유지하기 위해서 일정 수의 Pod 수를 유지해야 하거나, NoSQL 처럼 데이타 저장에 대한 안정성을 확보하기 위해서 쿼럼값만큼 최소 Pod를 유지해야 하는 경우 , 이런 노드 다운은 문제가 될 수 있다.
그래서 인위적인 노드 다운등과 같이 volutary disruption 상황에도 항상 최소한의 Pod수를 유지하도록 해주는 것이 PodDistruptionBudget (이하 PDB)이라는 기능이다. PDB를 설정하면 관리자가 노드 업그레이드를 위해서 노드를 다운 시키거나 또는 오토스케일러에 의해서 노드가 다운될 경우, Pod수를 일정 수 를 유지하지 못하면 노드 다운이나 오토스케일러에 의한 스케일 다운등을 막고, Pod 수를 일정 수준으로 유지할 수 있을때 다시 그 동작을 하도록 한다.
참고로 현재 PDB는 베타 상태이고 정식 릴리즈 상태는 아니기 때문에, 운영 환경에는 아직 사용하지 않는 것이 좋다고 합니다.
4. Cloud Auto Scaler (CA)
앞서 살펴본 VPA와 HPA가 Pod의 리소스 양을 늘려주거나 Pod의 수를 조정해서 부하를 감당하는 Pod 기반의 오토 스케일러라면 Cloud Autoscaler (이하 CA), Node의 수를 조정하는 오토 스케일러이다. AWS, Azure, Google Cloud 등 클라우드 인프라와 연동해서 동작하도록 되어 있고, 각 클라우드 서비스 마다 설정 방법이나 동작 방식에 다소 차이가 있으니, 자세한 내용은 클라우드 벤더별 문서를 참고하기 바란다.
기본적인 동작 방법은 같은데, Pod를 생성할때, Node들의 리소스가 부족해서 Pod를 생성할 수 없으면, Pod 들은 생성되지 못하고 Pending status로 대기 상황이 된다. Pending status 된 Pod를 CA가 감지 하면, Node를 늘리도록 한다. CA는 Pending status가 있는지를 감지 하기 위해서 (디폴트로) 10초 단위로 Pending status가 있는 Pod가 있는지를 체크한다.
Node Autoscaling 과정에서 주의해야 하는 점은 scale up 보다는 Node 수를 줄이는 scale down 이다.
CA는 10 초 단위로 scale up 이 필요한지를 체크한 후에, scale up이 필요하지 않으면, scale down 이 가능한지를 체크한다.
Node의 리소스(CPU,Memory)의 request 총합이 node 물리 리소스의 일정량 (디폴트는 50%)보다 작으면 scale down 을 고려 한다. 이때 리소스의 현재 사용량을 기반으로 하지 않음에 주의하기 바란다. Request를 넘어서 limit 아래까지 리소스가 사용되더라도 CA는 Node에 배포된 Pod들의 request 총합을 기준으로 한다.
Scale down은 scale down 대상 node의 Pod를 다른 node로 옮기고, scale down node를 삭제하는 방식으로 작동하는데,Scale down 조건이 되면, Node는 그 Node에서 돌고 있는 Pod들을 옮길 수 있는지를 먼저 확인한다.
-
컨트롤러 (ReplicationSet,Job 등)에 의해서 관리되지 않는 naked pod는 옮길 수 없다.
-
로컬 디스크를 사용하는 Pod는 옮길 수 없다.
-
Affinity,Taint 등의 조건에 의해서 옮길 수 없는 경우
-
만약 Pod를 CA에 의해서 이동하고 싶지 않은 경우, Pod를 “cluster-autoscaler.kubernetes.io/safe-to-evict:True” 옵션을 부여하여, CA에 의해서 Pod가 옮겨지는 것을 막을 수 있다.
-
그리고 뒤에서 소개하는 Pod Disruption Budget (PDB)에 따라서 Pod를 삭제를 조정한다.
조건에 부합하여 모든 Pod를 옮길 수 있다면, scale down node로 부터 해당 Pod를 삭제하고, 그 Pod 들을 다른 Node에 생성하고, scale down 대상 node를 삭제한다.
경우에 따라 특정 node를 CA에 의해서 scale down을 하고 싶지 않은 경우가 있을 수 있는데, 그 경우에는 node 에 다음과 같은 레이블을 적용하면 해당 Node는 Scale down에서 제외된다.
"cluster-autoscaler.kubernetes.io/scale-down-disabled": "true"
참고
https://bcho.tistory.com/1305 [조대협의 블로그]
https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale/
https://kubernetes.io/ko/docs/concepts/workloads/pods/disruptions/
https://kubernetes.io/ko/docs/tutorials/stateless-application/guestbook/
https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
https://kubernetes.io/ko/docs/concepts/workloads/pods/disruptions/
'Kubernetes & Docker' 카테고리의 다른 글
| [Kubernetes]쿠버네티스 설치부터 배포까지(kubespray 이용) (0) | 2020.08.21 |
|---|---|
| [Kubernetes]쿠버네티스 컨트리뷰터 되기 : 쿠버네티스 문서에 기여하기 (0) | 2020.08.19 |
| [Kubernetes 공식문서 파헤치기] Redis를 사용한 PHP 방명록 애플리케이션 배포하기 + PV, PVC, Affinity 사용해보기 (0) | 2020.08.10 |
| [O'REILLY] 쿠버네티스 패턴 (Kuerbernetes Patterns) (0) | 2020.08.10 |
| Kubespray와 Ansible을 이용한 Kubernetes 설치하기 - 4편 (2) | 2020.08.05 |